Pivoting is available in SQL Spreads Premium and above

From release 5.0 SQL Spreads can pivot data from rows in SQL Server into columns in Excel and save the data back to its unpivoted form into multiple rows in a SQL Server table.
When working with pivoted data you can Update, Insert and Delete rows of data in the SQL Server table from the pivoted view.
How to setup Pivoting in SQL Spreads
To set up pivoting, open the SQL Spreads Designer and select your database table in the Database tab. Then switch to the new Pivot tab to set up the pivoting:
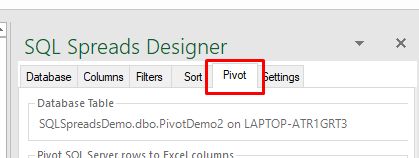
Select which database columns to use for pivoting
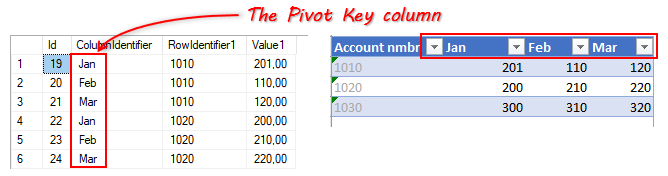
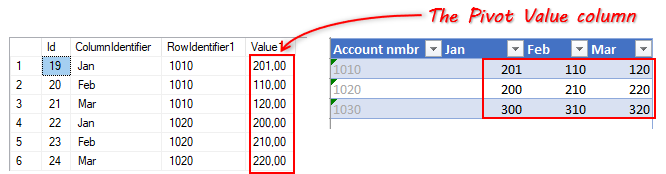
Pivoting uses two database columns to specify how the rows in SQL Server are pivoted into columns in Excel; the Pivot Key column and the Pivot Value column.
The Pivot Key column
The PivotKey column is the database column that holds the identifiers used to pivot the rows into specific columns in Excel. A typical PivotKey is a month.
You select the Pivot Key column in the first drop down list in the Pivot tab:
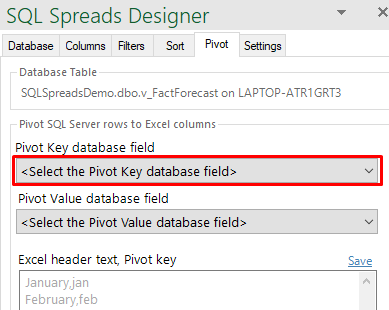
The Pivot Value column
The PivotValue column is the database column that holds the row values to be pivoted into columns in Excel:
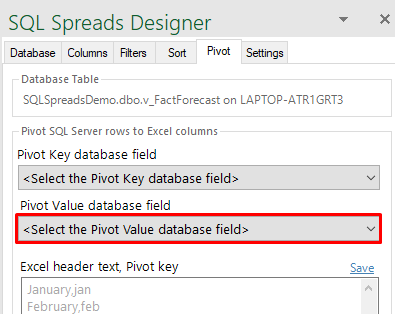
You select the Pivot Value column in the second drop down list in the Pivot tab:
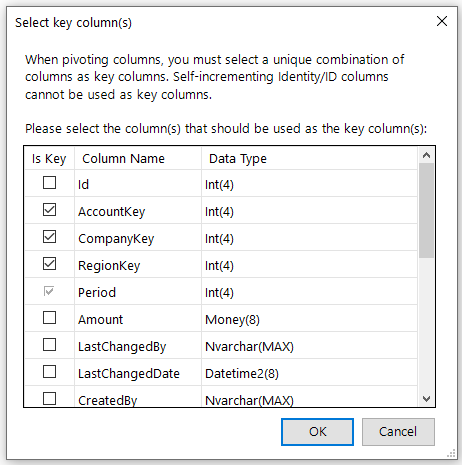
Setting up key columns when working in pivoted mode
When working with pivoted data in SQL Spreads, a row-unique ID column (such as an Identity key) cannot be used as the key.
Instead, a combination of database columns that together with the Pivot Key column uniquely identifies each row must be used. A typical setup is to use your business key columns as key columns in SQL Spreads.
To simplify the setup, SQL Spreads will show a Key selection dialog after you have selected your Pivot Key and Pivot Value columns:
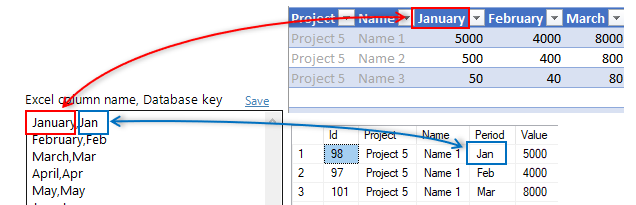
Select which database rows to show as columns in Excel
When you select the Pivot Key column, SQL Spreads will fetch the unique values in the database for that column and show them in the list in the Pivot tab:
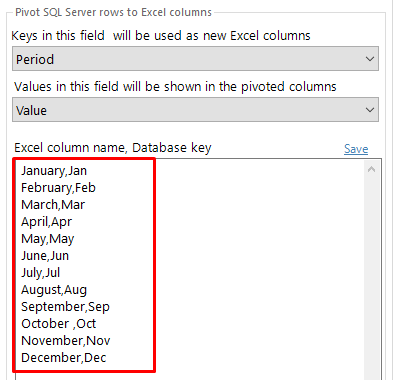
Each row in this list consists of two values separated by a comma;
- The first text, before the comma, is the header text to show in Excel
- The text after the comma is the Pivot key used to find the rows in the database table to pivot into this column.
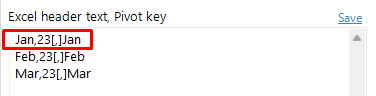
If the Pivot key, or the Excel column name contains commas, replace the separator with a comma in brackets [,]
How data is transformed into the Pivoted view
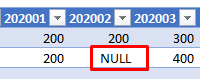
When a row does not exist in the database
If there is no row in the database for a specific Pivot key, SQL Spreads will show NULL in the cell in Excel.
Grouping of data
Normally, a database should only contain one row for each key combination.
If a table contains multiple rows for one key combination, SQL Spreads will show the sum of the values in the multiple rows for numeric values, the latest date for dates and the longest text for text columns.
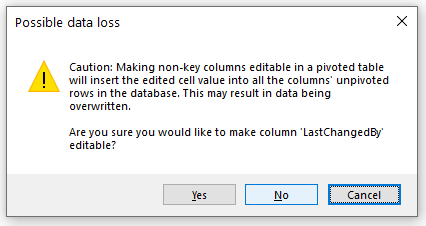
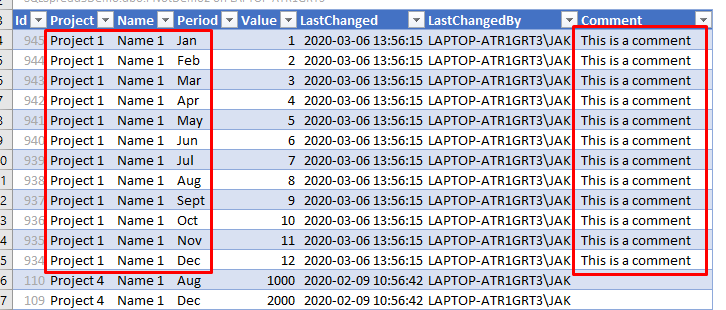
Non-pivoted, non-key columns - eg a comment
If you make a non-pivoted, non-key column editable, SQL Spreads will show you a warning dialog:
When you edit the data in one of these columns in Excel and save the data, SQL Spreads will update the column for all the unpivoted rows that exist in the database.
Example:
If you have a database table with a Comment column and make the Comment column editable in a Pivoted view in Excel, any updates that you do to the Comment column in Excel, will be saved into all unpivoted rows in the database table:
Pivoting FAQ
Are there any limitations when working with data in a Pivoted view?
Yes, there are a few limitations when working with data in pivoted mode:
- Conflict detection is not available.
- A worksheet with a Pivoted setup can only be configured using the SQL Spreads Designer and cannot be configured in the Advanced Setup.
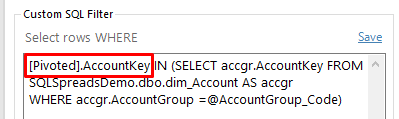
I get an "Ambiguous column..." error when using a Custom SQL Filter?
When using the Pivoting in SQL Spreads together with a Custom SQL Filter, you may get a SQL error message saying "Ambiguous column name 'SQL Column'":
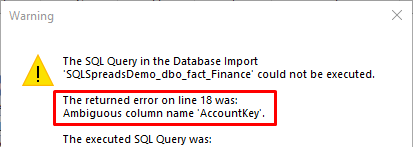
To avoid this error, please add the alias [Pivoted] before the column name mentioned in the error message, eg:
[Pivoted].AccountKey
The Custom SQL Filter will then look like this: